
Privacy and Efficacy – a Case for Returning to One-to-Many Targeting
by Grace Dillon on 30th Mar 2023 in Deep Dive
The sunsetting of third-party cookies adds a new dimension to advertising’s age-old question: how do I reach my target audience? It also complicates a central consideration to resolving this question – the collection, analysis, and application of users’ data.
Many in the industry have sought to lean hard into ‘privacy-first’ solutions that do not use cookies but still rely on granular, deterministic data. The same logic that drove the use of third-party cookies persists: more information allows for more niche targeting, and therefore more conversions. The industry as a whole is still animated by the paradigm of one-to-one marketing. But is this model really more effective? Moreover, how accurate are claims that these solutions are more privacy friendly? There’s evidence to suggest that, contrary to the assumption that hyper-targeting is the route to success, the technique can inhibit brand success, and that some leading post-cookie solutions are less secure than they may seem.
Digiseg has produced this Deep Dive in partnership with ExchangeWire. Digiseg maps digital advertising to household characteristics. Digiseg's cookie and tracking free technology can be used across all devices, media types and operating systems to target advertising and measure audiences for both campaigns and websites
In this Deep Dive, we will make the case for why one-to-many is the only truly privacy-centric form of targeting, and why advertisers should reconsider the view that it is less effective than deterministic solutions.
What will be lost when we lose cookies?

The downsides of using third-party cookies to provide targeted advertising are well-documented: it’s common consensus that these snippets of code infringe on the privacy of web users and aren’t actually that effective. Phasing them out, therefore, has been a good thing that has stirred the digital advertising industry to develop and explore more effective and respectful approaches to getting ads in front of interested people. Right?
The answer isn’t no, but it isn’t a resounding yes either. Stripping advertisers’ arsenals of third-party cookie-based solutions removes one intrusive targeting method. However, some of the cookieless solutions that have emerged or been heavily promoted in the run up to deprecation don’t necessarily deliver more privacy-preserving alternatives.
Research into three prominent solutions that use alternative identifiers found that, rather than improving the state of user privacy online, they “can make consumer surveillance in the Web dynamically wider, more persistent over time, and extra vulnerable to integration of first- and third-party data by advertisers”. The study found that all of the solutions accommodate longitudinal tracking, could enable individual users to be identified across different supply-side platforms (SSPs), and could even encourage advertisers to double down on user profiling by combining their first-party data with other data sources to build ‘look-alike’ audience segments.
These findings suggest that replacing third-party cookies with ID-based alternatives may not necessarily be the straightforward solution to safeguarding web users’ privacy. And they aren’t alone, with analysts citing similar concerns about a purported star of the cookieless future – data clean rooms.
Data clean rooms – not quite a tidy solution
Data clean rooms (DCRs) have been pitched as the go-to alternative to cookie-based targeting that allow companies to gain greater audience insight without compromising on privacy. While current data clean rooms differ in certain respects (something which the IAB are trying to change), all of them allow different sources of data to be aggregated and matched. Uploaded information is anonymised and kept within the confines of the clean room – it is not shared with participating companies.
At face value, using a DCR sounds like an effective way for advertisers to reach more people in a way that protects consumer information. However, the claim that data clean rooms are inherently privacy-preserving requires a closer look. These platforms may not grant participants user-level data, but that doesn’t mean that participants can’t find ways to access it. At present, there are no barriers to a publisher employing “ad observation” to link the personal data match keys of their own audiences segments to those stored in a data clean room, for example.
The fact that such a practice is theoretically possible suggests that the privacy of DCRs may be overstated. Participants should also take note of the lack of clarity regarding how clean rooms actually comply with privacy regulations, with approaches differing between providers: Snowflake place the onus of “applying the appropriate security and privacy rules, such as removing customers that haven’t consented to the use of their data” onto clean room participants; Habu, meanwhile, who say they “enforce the highest security and privacy standards” in their clean room, provide no clear information of whether and to what extent users are responsible for data security.
The assumption that clean rooms are infallible and inherently compliant is clearly misguided, and companies could risk falling foul of regulation if they continue to perceive them as such. Until there is greater clarity around who is liable for what, participants should be wary about just how ‘clean’ DCRs are.
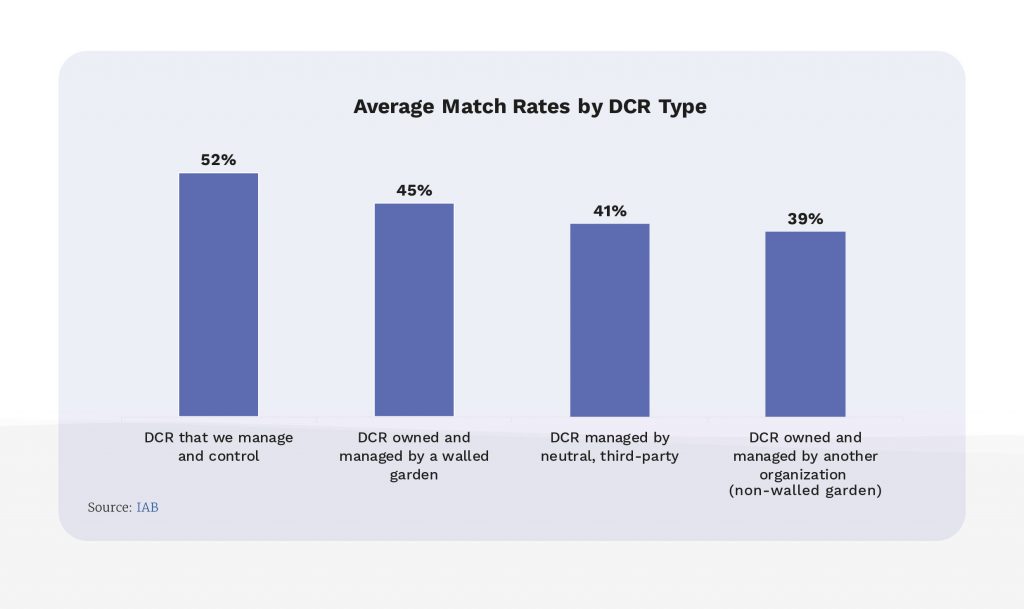
Scale is also a challenge. Match rates remain low, which is not a surprise when publishers only have data on 3-10% of their visitors. The IAB State of Data 2023 report sums it up bluntly: “Sub-par match rates threaten the overall efficacy of DCRs.”
Yet perhaps the central flaw of DCRs, and ID solutions generally, is that, at their core, they are still highly dependent on identity. This leaves them exposed to tightening privacy regulation and significantly limits their potential to provide scale. But surely the capacity that these solutions provide to deliver precision audiences makes it all worthwhile? Not necessarily.
Hyper-targeting – overhyped?
The purpose of audience data, cookie-based or ID-based, is to enhance the capacity to target specific audiences. In digital, the goal has been to achieve what legacy media like TV could never realise: one-to-one communication. Digital audience data has sought to be deterministic since the beginning – the goal being what we will refer to as hyper-targeting. The notion that narrowing down targeting to segments of people who may be more interested in a particular product or service will achieve better results has captivated our industry for years, and been central to the development of much of our technology. However, it may not be true.
From a strictly logical perspective, reaching out to a smaller pool of people involves avoiding a large portion, automatically restricting the number of potential conversions. Furthermore, the conventional belief that targeting a smaller group is preferable because they possess qualities that make them more inclined to engage is not always accurate. This was the case for P&G, who found that sales of Febreeze air freshener stalled when they targeted Facebook ads exclusively to people with families and pets, but improved after the campaign was opened up to anyone over the age of 18. This discovery led the consumer goods giant to conclude that they “targeted too much” and to roll back on hyper-targeting via Facebook.
Assuming that a small portion of the population will drive the majority of a brand’s sales is misguided at best. How many times can you expect the same consumer to buy a certain product, especially big ticket items, like mattresses or cars? In the words of Byron Sharp, “Sales growth won’t come from relentlessly targeting a particular segment of a brand’s buyers”. In the long term, limiting outreach to those who are already familiar with a brand risks shutting it away from wider public consciousness, causing it to “lose its place in culture”.
Hyper-targeting isn’t as effective as many commonly believe, and a big reason for this is because personalisation is challenging. Effective personalisation depends on having access to high quality data, something which has long been difficult and will continue to be impacted by new data laws. Moreover, the growing fragmentation of audience attention makes targeting more difficult and more expensive, and consumers’ increased awareness and concern over how companies use their data has made some less receptive to targeted advertising.
These factors — the privacy issues posed by alternative IDs and clean rooms, and the limitations of hyper-targeting — lead us to one simple conclusion: that probabilistic targeting is the way forward.
Privacy does not mean compromising performance

We believe that there’s a case to be made for returning to mass reach, or one-to-many advertising based on probabilistic data. In our view, this is the only audience model that can be truly private, as it is the only model that avoids using personal data . Better still, there’s evidence that it can be more effective than hyper-targeted approaches.
Probabilistic targeting makes “best-guess inferences using data that is not traditionally considered personally identifying,” for example, contextual or IP addresses mapped to neighbourhoods. This means that not only does probabilistic data afford more privacy to web users, but also that it’s future-proof: as we’ve seen from the flurry of new privacy laws being introduced across the world in recent years, and the increased scrutiny of Big Tech companies’ handling of user data by authorities like the European Union, regulation is only going to get tighter. Navigating new legislation will become trickier, and the penalties for failing to comply will be severe. Therefore, investing in probabilistic-based solutions now will prevent the need to give up deterministic ones to meet future regulatory changes.
A probabilistic approach could even address the privacy issues that currently impact data clean rooms. The challenge at the very core of the clean room model is that it is anchored by personally identifiable information. As Ampersand chief privacy officer and general counsel Noga Rosenthal notes, “How does this solve the identity issue or the cookie issue? I couldn't figure it out. I looked at all the [clean room providers'] websites. They all said the same thing about being the answer to the loss of the third-party cookie, but nobody explains how."
Dennis Dayman, resident chief information security officer at Proofpoint, illustrates the issue clearly: "I'm not giving away and I'm not selling, but in essence, you are processing that data. And I'm looking at [GDPR] here. Let's get into the real definition of it. Did you tell my wife, who might have given you that data because she shopped at Sephora? Did she know that you were going to try to pull more information about her or try to do some more matching?" In other words, consent should not be transferable.
As Audigent CEO Drew Stein asserts, feeding probabilistic data into clean rooms would make the technology genuinely privacy preserving for consumers and more effective for advertisers, as “Predictive data sets can achieve far greater actionable scale across the entire open web."
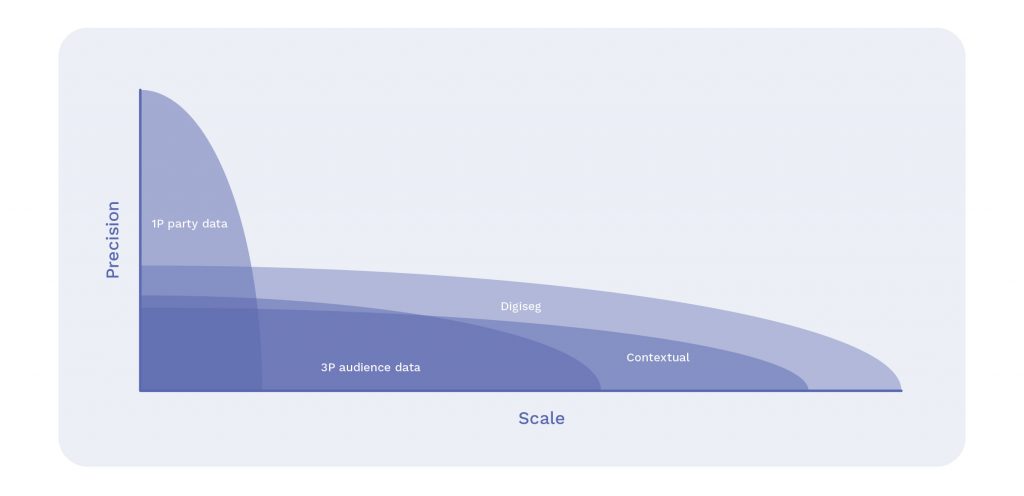
Greater fragmentation and the relative scarcity of deterministic data outside of walled gardens are already hindering advertisers’ capacity to accurately target their campaigns, and will only cause hyper-targeting to become more expensive. Uniting probabilistic approaches and mass reach offers advertisers greater potential to get their message across to consumers.
Returning to mass targeting (as traditionally seen in TV, radio, and print) will involve relinquishing the impulse to place identity at the centre of targeting. However, it is possible, and, if done effectively, can be very rewarding. Two such approaches that have already seen adoption are contextual targeting and using offline demographic data.
Contextual echoes the traditional model of mass media – for instance, a furniture brand might bid for inventory within the ad break of a home renovation TV show, or an activewear brand might buy space within the sports pages of a newspaper. While contextual has previously been dismissed as primitive, new developments have made the approach more accurate, and it has been found to increase purchase intent by 63%. As it doesn’t rely on user data, contextual advertising is now considered “a solid segmentation method that’s inherently anonymous”.
Evolutions in modelling and methodology coupled with the strength of digital delivery mean that leveraging offline demographic data is more fruitful than during the heyday of broadcast TV: moving on from panel-based modelling, firms can now use aggregated location information such as or IP addresses matched to neighbourhoods to segment the population and deliver more targeted ads. A perfect example is an anonymised household targeting campaign for BMW. This approach is intrinsically anonymous, and can combine reach and precision for more effective messaging.
None of this is to suggest that returning to a mass-reach approach is easy, but if the trade-off between reach and precision is right, the advertiser wins. Embracing probabilistic data and combining it with mass reach can help advertisers avoid mounting privacy concerns and achieve better results than they may have previously believed.
The industry view

We’ve established why we believe that probabilistic targeting is worthy of further attention and investment as we approach the post-cookie era. But what does the industry make of the shift to cookieless and the importance of probabilistic targeting? Patrick Zinga, automated media, data and technology lead, marketing – data driven media at Heineken UK; Sophie Toth, co-founder of The Women in Programmatic Network; and Brandon Keenen, CMO at Ziglu, share their thoughts with us.
What have been the biggest challenges you've faced since the shift away from third-party cookies and identifiers?
PZ – It’s been difficult to build towards a singular consumer view across all touchpoints to manage and enhance the consumer journey and accurately measure our impact across key media touchpoints. Measurement is always an issue and having the right tech solution in place hasn’t been the easiest to resolve, but we are moving towards platforms that enable us to still be able to generate enough accurate insights from our key consumers in order to inform future planning.
ST – It's been a long time, and we are still looking for a single/unified solution for post third-party cookie deprecation.
Publishers, tech vendors, advertisers, and agencies have been evaluating and testing new IDs, but the most significant challenge is the disconnection between parties, and we are facing:
- scaling issues
- performance issues
- comparison issues;
and after years, we can still say that the world of IDs is unknown. Also, commercialising essential targeting components is not ideal and indicates an extra fee in the chain.
BK – The transition away from third-party cookies and identifiers has exacerbated the challenges in performance marketing. This has prompted a decrease in social media performance, due to platforms’ misuse of data, manipulative targeting behaviours and platforms with a political bias. This irresponsibility has created an environment where consumers are less engaged with content and advertising. On top of this, big platforms are more empowered to protect their data by building bigger walls around their gardens.
In order to succeed in this new landscape, both publishers and advertisers must make fundamental changes to their data strategy. This includes increased investment in clean rooms, consensual user experiences, quality content production and reciprocal and affiliate marketing programmes. By creating accurate probabilistic look-alikes, seeking out partnerships in "clean" data and building a deeper understanding about our customers, we can build compliant first-party targeting campaigns and drive higher, longer-valued performance.
There is currently significant focus on "Identity resolution", but what role do you believe probabilistic targeting will play in the post-cookie world?
PZ – Deterministic is probably the better space to play in and as more brands and publishers focus on growing their first-party data, we will see the scale issues we currently have no longer be a significant problem. Plus, ad tech should essentially be better at helping increase match rates in the future as the technology improves. Probabilistic still plays a part because it at least allows us to make assumptions based on various data points, in order to create persistent identifiers.
ST – ID graphs and the growing need for richer deterministic data on a single user can bring a new way of digital targeting and personalisation, but in contrast, we will always have visitors without common data touch points and data sets for composing ID graphs. Therefore, we need to combine different tactics and strategies to push relevant ads or messages the consumers' way.
On the other hand, using ID graphs and segments, marketers can use probabilistic approaches: such as behavioural data overlay to the seed audiences, and creating lookalike models or setting independent conditions in their DMPs or CDPs for users who don't have the crucial data for ID graphs.
We are in the evolutionary phase of the next generation of digital advertisements. Most publishers (without login and subscription) rely heavily on probabilistic data and are trying to find their way towards ID graphs. However, we have more years ahead to create a solid structure across digital media globally.
BK – The shift away from third-party cookies has put a greater emphasis on building rich, GDPR-compliant first-party data sets. This shift is pushing advertisers and publishers away from an emphasis on performance and towards a focus on delivering exceptional customer experiences. No longer can brands rely on a sub-par product with aggressive and skilled marketing. Instead, brands must focus on communicating with existing customers, building up referrals through programmes and word-of-mouth, and delivering exceptional experiences. Identity resolution and probabilistic targeting will still be key in this post-cookie world.
Is it a misconception that contextual is the only viable form of cookie- and ID-free targeting?
PZ – For broad marketing, I agree that contextual is and always has been a viable solution. Even when it comes to personalisation of messaging, you can still be relevant by diving into the assumed interests of the audience, utilising semantics aligning with the content on the page. This is not the only solution however and there is a lot being done to grow our own first-party data, publisher cohorts based on logged in data and clean rooms where we can still gather insight with publishers and retailers, create audiences using partner data to activate against, or create lookalikes to drive better effective marketing.
ST – Contextual targeting is just one of the forms of independent solutions from cookie and ID, but not the only one, and it has its limitations.
We know many other targeting options: viewability, performance-based (ad unit level), postcode-level targeting, just to name a few.
We have to use and consider these technologies as complementary solutions and combine their capabilities to cover and maximise our reach with relevant information in a privacy-compliant and user-first way.
Eventually, the control of the data will shift back to its owners, who are the end users and customers, and this will be the right outcome.
BK – Contextual targeting has been used for some time and does have its advantages. However, third-party targeting was far more effective. Advertisers and publishers can still collect rich data from their audiences that goes beyond context, allowing for more targeted advertising and better results. In cookie- and ID-free targeting, partnerships with publishers who understand their audience, creators who are honest and transparent about their audience, cross-functional marketing partner programs and affiliate partnerships with allowed cookies for business purposes (not ID-free) will provide more effective targeting options that we can build on.
There will never be only one method. We have to be precise when it comes to measurement and targeting and ensure that it is based on real numbers from real sources and truly drives brand growth over vanity metrics.
 Download Report
Download Report 





Follow ExchangeWire