The 404bot, or No Bot at All?
by Mathew Broughton on 3rd Mar 2020 in News

Following the recent news of the 404 bot scheme which purportedly generated fake browser data in order to harvest advertiser media spend, Dr. Augustine Fou, independent ad fraud researcher, writes exclusively for ExchangeWire on the potential limitations of fraud filtering technology.
This week brought news of yet another bot that ate 1.5 billion ad impressions through fraud. But this is both good news and fake news. On the one hand, the reports of this 404bot made people realise that industry standards and protocols like ads.txt are good ideas in theory. But without vigilant action by both buyers and sellers alike, the intended outcomes (lower fraud) don’t just magically happen. Publishers have to add ads.txt files to their sites to tell buyers who are authorised to sell their inventory. But buyers must also check those ads.txt files in order to know if bad guys are still ripping them off by pretending to be good publishers (i.e. domain spoofing).
What’s additionally interesting is that folks are just now realising that fraudsters are highly efficient with their use of resources to commit fraud. For example, why even create a fake website when you can make money just by passing a url that appears to be from a legit publisher’s website in the bid request? Any resource, time, and cost saved, means more profit margins retained from the fraudulent activity. In the case of the 404bot, there weren’t even real webpages; they just passed fake urls in the bid requests and still got paid. When the fraud detection company checked the urls, they got 404 errors - web server-speak for “page that doesn’t exist.”

Dr Augustine Fou, Independent Ad Fraud Researcher
I’m certainly glad they are checking that now; but the question is why weren’t they checking that all along? It would have been such an easy way to see the fraud occurring in broad daylight that their tech didn’t catch before. Like I’ve been saying all along, just because you can’t detect fraud doesn’t mean it’s not there. You have to keep looking, to see all the stuff the bad guys have been doing all along, but that you simply didn't know about. The problem of “you didn’t know what you didn’t know” is not solved by assuming everything is fine and not looking more closely, all. the. time.
This reminds me of another example from 2017, Sports Bot, which didn’t even exist. It was a PR scheme by another fraud detection company to get publicity for itself. Unfortunately, that came at the expense of good publishers, who got a flurry of phone calls from buyers asking about their exposure. But soon it became clear that the verification tech company didn’t even know how the fraud occurred, and was merely speculating. Quoting from their press release: “Sports Bot used highly sophisticated techniques to fraudulently load ads on the affected sites without the site owners’ consent, leveraging a new methodology that allows it to monetise inventory on premium domains... Although the bot’s specific deployment methodology is not yet known, it may originate with malware downloaded unwittingly onto users’ computers.”
My code was measuring on some of those sites they claimed were hit with Sports Bot but there was no surge in bots or even much bot traffic at all. None of what they claimed in the press release actually occurred; what did happen was they analysed billions of bid requests that were spoofing major sports brands’ domains and found massive amounts to be fraudulent. No bots ran wild on those websites and no ads actually ran - it was just faked domains in the bid request just like the 404bot case from this week. But this fraud detection company also called it Sports Bot so their press release could tout their “Next Generation Fraud Detection Algorithm” had found a gigantic bot. And hilariously, TAG eagerly jumped in to congratulate them with a quote in the press release.
So, two lessons to be learned, if you so choose. Fraud is done efficiently -- without even needing to set up fake websites and buy traffic to load webpages. The fraud is already successful, for years, by passing faked urls in bid requests. The other lesson is that some fraud detection tech is also completely fake too - they can’t detect anything. Their main skill is in writing press releases that say they detected something, when that something was also fake. You see the trend here?
If you are still unconvinced, check these examples out. The Uber lawsuit against 100 mobile exchanges accused them of falsifying placement reports (to make it appear ads ran on legit sites and apps) and of fabricating transparency reports, when no ads were even run at all. Further back, in 2016, we showed how Google Analytics can be tricked into thinking there was traffic, when no traffic actually occurred. This is done simply by loading the analytics tracking tag repeatedly and passing in variables that made it appear real. There are also “naked ad calls” where ads are called directly, without the need for a webpage to load, to save bandwidth.
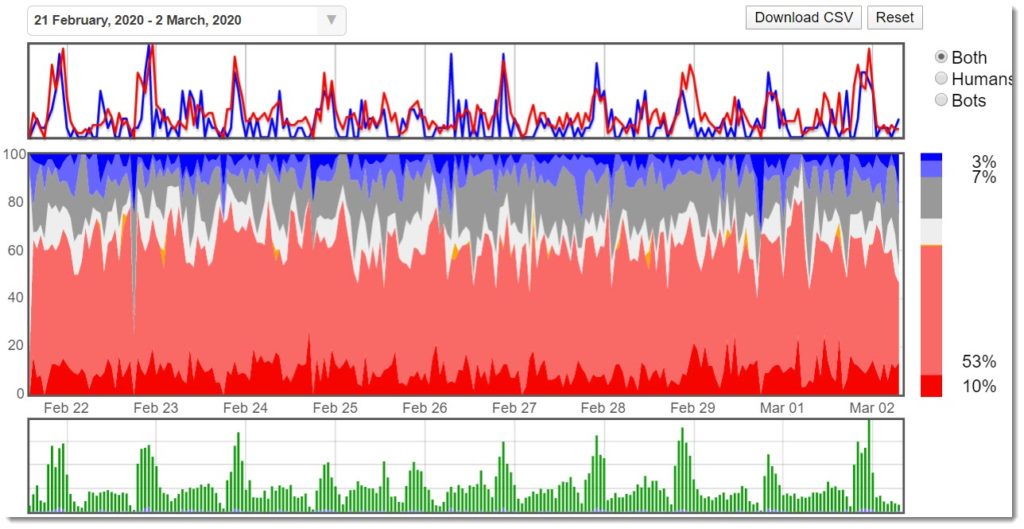
We have many other examples over the years that show that fraud detection doesn’t detect and fraud filters don’t filter. Can you tell when the fraud filter was turned on in the following chart? No, we can’t either (it was turned on on Feb 26th).
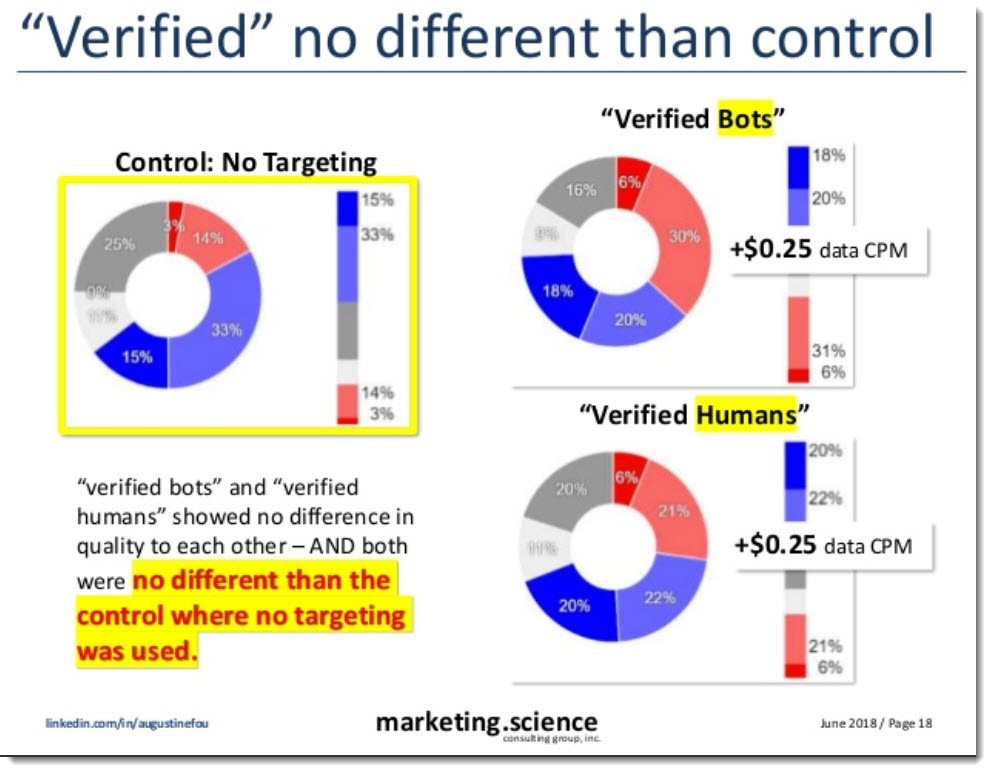
Other examples I’ve published over the years show that “verified humans” and “verified bots” (segments being sold for targeting by a DMP) were no different than each other, and also no different than control, where no segment was targeted.
And four different fraud filters turned on and off sequentially did not change the level of bots/NHT or naked ad calls in the campaign. So what were they filtering if no change were even observable? Note that all of these services and segments cost more -- marketers paid for it and assumed they work. But if you can’t detect any change when using the fraud filters or verification vendors or not, shouldn’t you call that “smoke” -- as in “smoke and mirrors?” Yeah, I think so.

And please be sure that you are not THAT marketer that just paid millions of dollars for an Excel spreadsheet, and assumed that meant your billions of ad impressions actually ran, somewhere.







Follow ExchangeWire